
The keys to data science are data, and a question or need to answer. Let’s assume your company has plenty of both. Data science is just one means to uncover important info for your company.
Here’s a step-by-step guide to getting started with data science using Microsoft Fabric in your company.
Step 1: Understand the Microsoft Fabric Platform
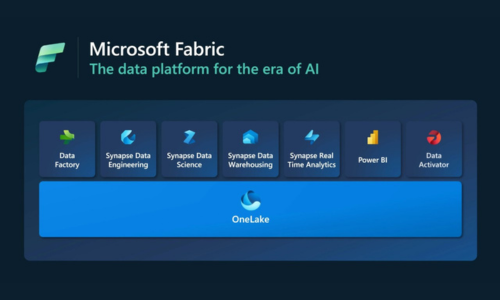
Microsoft Fabric is a robust platform that brings together data science, data engineering, and data analysis. It facilitates end-to-end data science workflows, enabling data enrichment and business insights. Before diving in, familiarize yourself with the platform’s capabilities and how it can cater to your specific data science needs.
If you are already using Power BI, or other components of Fabric, you’ve already got a great start. Data science needs data, a need or question to get answers to, and a means to get that answer. If you have workspaces and data established in Fabric, you’ve already made the first step. If you have not, follow the next steps to get things started.
Step 2: Set Up Your Workspace
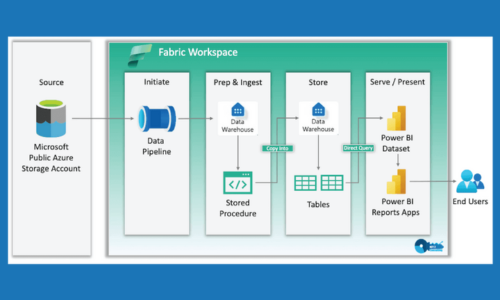
Begin by creating a workspace within Microsoft Fabric. This will be your central hub for managing data, notebooks, experiments, and models. Ensure you have the necessary permissions and access to the data sources that will be used for your data science projects.
The workspace is the centerpiece of the Data Science work, and houses most of the tools and items. Start small – one question or need, with a limited scope. You can always branch out to other areas, other workspaces, other needs.
Now that you have a home for your Data science needs, time for data.
Step 3: Data Ingestion and Cleansing
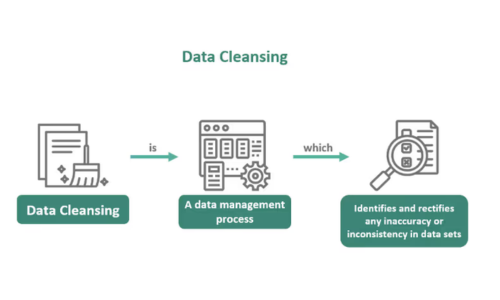
Data ingestion is the first practical step in your data science journey. Use Microsoft Fabric’s tools to connect to various data sources and ingest data into a centralized Lakehouse. Once ingested, cleanse and prepare your data using tools like Apache Spark and Python-based libraries to ensure quality and consistency.
This step is critical, and sounds easy to say, but will require the most effort. If you are working with your data that has already been prepped, Congratulations – as you’re in better shape than most. If not, decide what data you will need to help you answer that question or need, and begin to gather. Now is also a great time to plan with those who normally handle data within your area, as prepping for the future and sharing the data is part of the best practice in data governance. More on that in another blog!
Step 4: Exploratory Data Analysis (EDA)
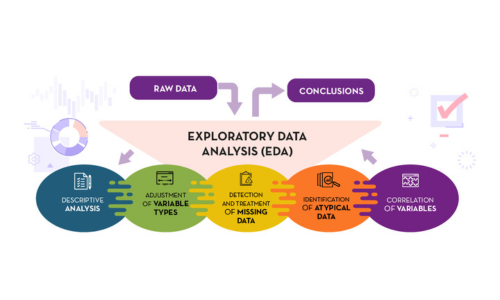
Exploratory Data Analysis is crucial for understanding the underlying patterns and anomalies in your data. Utilize Microsoft Fabric’s notebooks to perform EDA, leveraging built-in experiences on Spark and Python-based tools like Data Wrangler and SemPy Library. Not a python or coding expert? No worries, Copilot within Fabric can help you get the code you need. Microsoft Fabric and notebooks can use a plethora of languages, so if you have in-house expertise in another coding language, use that.
Step 5: Model Training and Experimentation
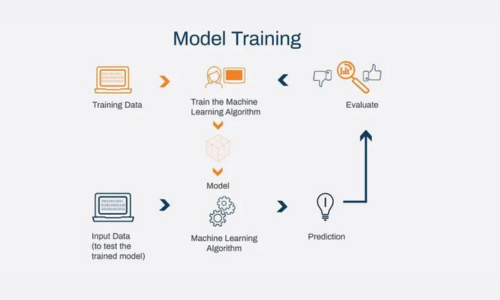
With clean data in hand, it is time to train machine learning models. Before going further make sure you have stored that data in a Lakehouse or warehouse within Fabric for easy retrieval and collaboration. Microsoft Fabric provides seamless experience for creating experiments and tracking model training metrics with MLflow. You can also use Fabric notebooks to train models using various machine learning algorithms.
Training data is matter of sampling some of your data to use to “train” your model to look for the answers to your question(s) in mind. Remember to be focused and start small, no World Hunger type of questions.
The remaining data, not part of the training, is used for analysis.
Step 6: Model Scoring and Deployment

After training, score your models to evaluate their performance. Microsoft Fabric allows you to run batch predictions and save the results to the Lakehouse. You can then register and track trained models using MLflow and the Fabric UI. The nice part is that most of this happens seamlessly, without much intervention on your part. It is always good to know what is happening in each step, but scoring and modeling batches can help fine tune that model. Once you’ve happy with the model, time to get it ready for widespread use. This is matter of publishing the model into the Fabric workspace.
Step 7: Visualization and Insights
The decisive step is to visualize the predictions and insights generated by your models. Microsoft Fabric integrates with Power BI, enabling you to create interactive reports and dashboards that can be shared across your organization for data-driven decision-making.
You can also use the model in other apps or code to ingest new data and gain further insights on your questions and needs. The model is now ready for any new data, or revisit older data, looking for trends and analytic insights.
Conclusion

Implementing data science in your company using Microsoft Fabric requires a structured approach, starting from understanding the platform to visualizing the insights. By following these steps, you can leverage the power of data science to uncover valuable insights and drive your company’s success. The more you learn, the better your Data analytics get, and provide better insights for your company. But do not let the concept of data as a science keep you from exploring.
There are a lot of steps and considerations, but getting started in Data Science can be achieved with some focused interest and tools found in Microsoft Fabric. Once you have started, you’ll soon see the limitless possibilities.
Collection Intelligence has experts who can assist you in the journey, or work with you to plan and implement an enterprise-wide data solution. If you need us for large or small efforts, we are one contact away.
Remember, start small, but keep the end game in mind – plan for future use, sharing and collaboration.